UUID vs ULID vs NanoID: Which Random ID Format Should You Use in 2026?
Side-by-side comparison of UUID v4, ULID, and NanoID — format, length, sortability, collision probability, database performance, and a decision guide for your next project.

This article is currently only available in English. A ภาษาไทย translation is coming soon.
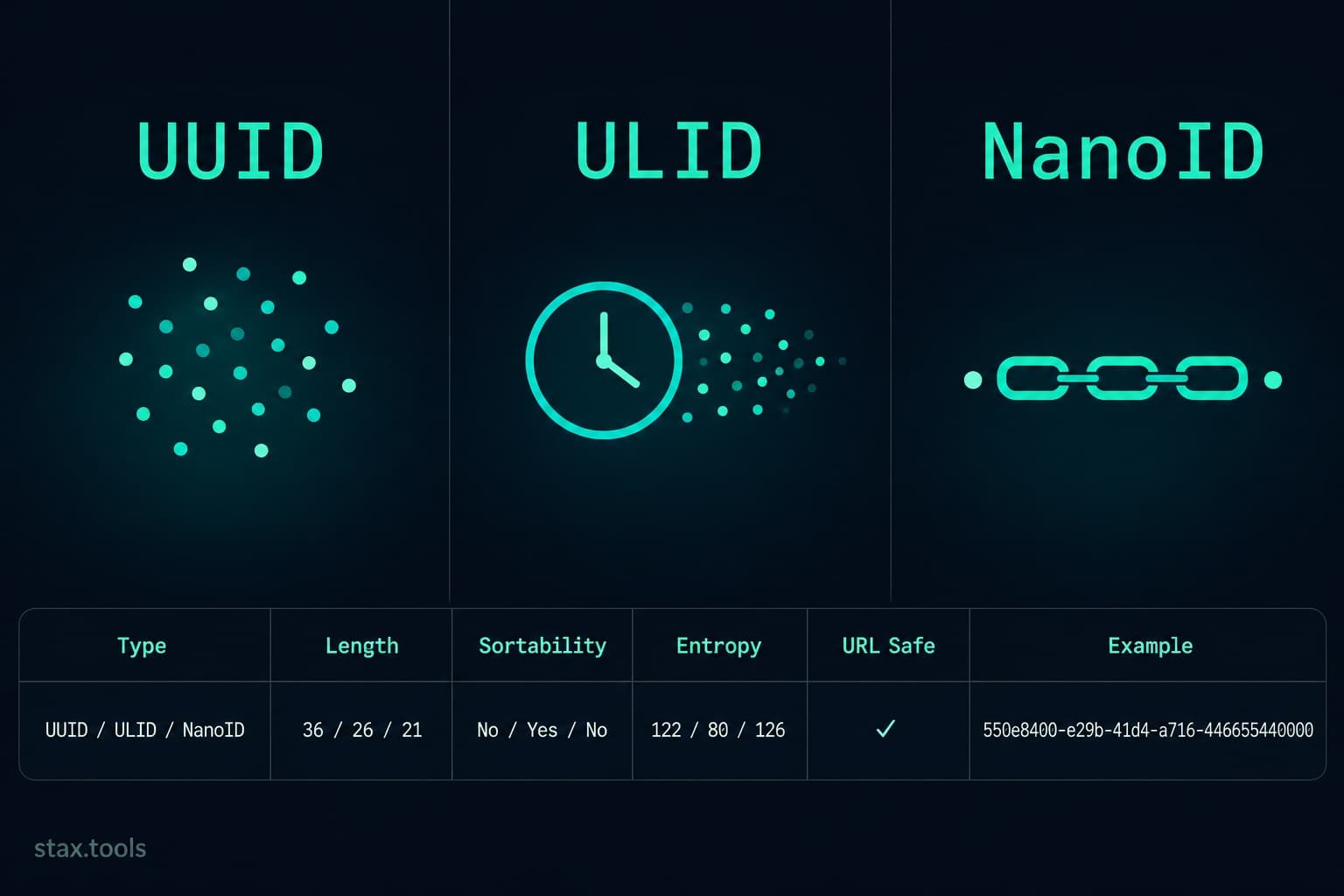
Every database row, every API resource, every distributed event needs an identifier that is unique, unguessable, and safe to expose in a URL. UUID has been the default answer since the RFC 4122 standardised it in 2005. But two newer formats — ULID and NanoID — solve problems that UUID quietly ignores. Here is the complete comparison.
The quick lookup table
| Property | UUID v4 | ULID | NanoID |
|---|---|---|---|
| Length (chars) | 36 (with hyphens) | 26 | 21 (default) |
| Length (bytes) | 128 bits | 128 bits | 126 bits (default) |
| Character set | Hex + hyphens | Crockford Base32 | URL-safe alphabet |
| Sortable | ❌ Random | ✅ Lexicographic (ms precision) | ❌ Random |
| Monotonic within ms | ❌ | ✅ (spec v1.0+) | ❌ |
| URL-safe | ✅ (with encoding) | ✅ | ✅ |
| Collision probability | ~50% at 2.7×10¹⁸ IDs | Same as UUID | ~50% at 2.7×10¹⁵ IDs |
| Officially standardised | ✅ RFC 4122, ISO/IEC 9834-8 | Unofficial spec | Unofficial, widely adopted |
| Database index efficiency | Poor (random → page splits) | Good (ordered → sequential inserts) | Poor |
| Human readability | Low | Medium | Low |
| Library size (JS) | Built-in (Web Crypto API) | ~1 KB | ~1 KB |
Generate a UUID, ULID, or check entropy of any ID at the Stax UUID Generator.
UUID v4: the safe default
UUID v4 is 128 bits of (near-) random data formatted into 32 hex characters with four hyphens: 550e8400-e29b-41d4-a716-446655440000. The 122 meaningful bits come from a cryptographically secure random number generator — the remaining 6 bits encode the version and variant.
Why most projects still use it:
- Supported natively by every database, every ORM, every language standard library
- RFC standardised — auditors, architects, and compliance teams recognise it immediately
- Zero coordination required across distributed systems — two nodes generating UUIDs simultaneously will not collide in any realistic scenario
- Web Crypto API (
crypto.randomUUID()) ships in all modern browsers and Node.js 15+
Where it falls short:
The 36-character representation with hyphens is 44% longer than ULID and 71% longer than NanoID for the same amount of information. In a URL (/orders/550e8400-e29b-41d4-a716-446655440000) this is awkward. In an indexed database column, random UUIDs cause index fragmentation: because each new row's ID is random, InnoDB and similar B-tree engines must insert it into the middle of the index tree rather than appending to the end. At high insert volume, this triggers page splits — a measurable performance cost that begins to matter around 10M+ rows with frequent inserts.
ULID: UUID with a timestamp prefix
ULID (Universally Unique Lexicographically Sortable Identifier) was designed by Alizain Feerasta in 2016 specifically to fix the sortability gap. A ULID looks like: 01ARZ3NDEKTSV4RRFFQ69G5FAV.
The structure is precise: the first 10 characters encode a Unix timestamp in milliseconds (giving a range from 1970 to approximately the year 10889). The remaining 16 characters are random. Everything uses Crockford Base32, which deliberately excludes letters that look like numbers (I, L, O, U) to reduce transcription errors.
What this buys you:
Because the timestamp prefix is always increasing, new ULIDs sort after old ones lexicographically. In a B-tree index this means new inserts append to the right-most page — the same pattern as an auto-incrementing integer. Benchmarks from Percona and similar sources report 30–50% faster bulk inserts in InnoDB compared to UUID v4 on tables above 10M rows, because page splits are near-eliminated.
The monotonic extension (ULID spec v1.0) solves the edge case where two IDs are generated within the same millisecond: the second ID's random component is incremented by one rather than re-randomised, guaranteeing strict ordering even within the same timestamp.
The tradeoff:
The timestamp leaks creation time. If your IDs appear in URLs or API responses, an attacker can determine approximately when a resource was created, infer insertion rate, and enumerate records within a time window. For most applications this is acceptable. For systems where creation time is sensitive (medical records, financial transactions, whistleblower platforms), UUID v4 is safer.
NanoID: the compact URL-safe choice
NanoID was created by Andrey Sitnik (creator of PostCSS and Autoprefixer) in 2017. The default output is 21 URL-safe characters: V1StGXR8_Z5jdHi6B-myT.
At 21 characters with an alphabet of 64 symbols, NanoID has 126 bits of randomness — slightly less than UUID v4's effective 122 bits but more than enough for any practical use case. The collision probability only reaches 50% after approximately 2.7 × 10¹⁵ IDs, which is 2.7 quadrillion. You will not collide.
What makes it different:
The alphabet is configurable. You can restrict it to digits only (0-9), lowercase only, or any custom set — making NanoID useful for short readable codes (discount coupons, referral codes, short links) where you want a specific character set or length. At 8 characters with digits+lowercase, you get ~47 million unique IDs before a 1% collision probability — sufficient for most coupon systems.
NanoID uses the Web Crypto API (or crypto.randomBytes in Node.js) rather than Math.random(), so it's cryptographically secure. The library is approximately 130 bytes when using the built-in version — the smallest of the three.
The catch:
No sortability, no timestamp, and it's not an official standard. Some enterprise contexts require identifiers to conform to UUID RFC format — NanoID won't pass those validators.
The decision guide
Use UUID v4 when:
- You need a universally recognised standard (compliance, third-party integrations, legacy systems)
- Insert volume is moderate or table size is under ~10M rows
- You don't control the ID column type in an external database
- You want zero external dependencies (Web Crypto API is sufficient)
Use ULID when:
- Your primary concern is database index performance at high insert volume
- You need rough chronological ordering without a separate
created_atcolumn - You're building event logs, audit trails, or timeseries data
- Creation timestamp exposure in the ID is acceptable
Use NanoID when:
- URL length matters (short links, REST resource IDs in URIs, QR code content)
- You need a custom alphabet or character set (coupon codes, referral slugs, invite tokens)
- You're building for a browser environment where bundle size is a constraint
- Sortability is irrelevant to your use case
What about UUID v7?
RFC 9562 (published May 2024) introduces UUID v7, which is effectively ULID with the UUID format wrapper: 48 bits of Unix timestamp in milliseconds + 74 bits of random data, encoded as a standard UUID string. UUID v7 gets you ULID-style sortability within the familiar xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx format.
Most major database engines (PostgreSQL 17+, MySQL 9+) and ORMs are adding native UUID v7 support through 2025–2026. If you need ULID's performance benefits but must stay within UUID format constraints, UUID v7 is the answer. It is not yet as widely supported as v4 but adoption is accelerating.
| Format | When it's the best choice |
|---|---|
| UUID v4 | Default. Safety, compatibility, no dependencies. |
| UUID v7 | You need UUID format but want B-tree performance. Check DB/ORM support. |
| ULID | Maximum sortability + performance without UUID format constraints. |
| NanoID | Shortest URL-safe IDs, custom alphabets, coupon/token generation. |
Generating all three
The Stax UUID Generator produces UUID v4 using crypto.randomUUID() — the same entropy source as all three formats when running in a modern browser. Your IDs are generated entirely in your browser; nothing is transmitted anywhere.
For ULID and NanoID generation in production code:
- Node.js:
npm install ulid/npm install nanoid - Python:
pip install python-ulid/pip install nanoid - Go:
github.com/oklog/ulid/v2/github.com/matoous/go-nanoid
By Harshil Shah, developer and founder at Stax Tools. Collision probability calculations based on the birthday problem formula P(collision) ≈ 1 − e^(−n²/2H), where H is the hash space size.
Sources & methodology
- RFC 9562 — Universally Unique IDentifiers (UUIDs), IETF, May 2024
- ULID Specification v1.0.0 — github.com/ulid/spec
- NanoID — github.com/ai/nanoid (Andrey Sitnik, 2017)
- Percona Blog, "UUIDs are Popular, but Bad for Performance" — percona.com, 2019 (InnoDB insert benchmarks)
Harshil
Developer & Founder, stax.tools
Harshil is the developer behind stax.tools, building privacy-first tools that run entirely in your browser.
More by Harshil →Found this useful?
Browse 235+ free privacy-first tools — no login, no uploads, instant results.